En el ámbito de la
estadística, la
mediana, representa el valor de la variable de posición central en un conjunto de datos ordenados. De acuerdo con esta definición el conjunto de datos menores o iguales que la mediana representarán el 50% de los datos, y los que sean mayores que la mediana representarán el otro 50% del total de datos de la muestra. La mediana coincide con el
percentil 50, con el segundo
cuartil y con el quinto
decil.
Sabemos que la mediana es el valor medio en un conjunto de valores ordenados. Corresponde al percentil 50 o segundo cuartil (P50 o Q2). Los pasos son: 1) Arregla los valores en orden del menor al mayor 2) Cuenta de derecha a izquierda o al revés hasta encontrar el valor o valores medios. Ejemplo: tenemos el sig conjunto de números 8,3,7,4,11,2,9,4,10,11,4 oredenamos: 2,3,4,4,4,7,8,9,10,11,11 En esta secuencisa la mediana es 7, que es el número central. Y si tuviésemos: 8,3,7,4,11,9,4,10,11,4, entonces ordenamos: 3,4,4,4,7,8,9,10,11,11 y la mediana (Md) está en: los números centrales son 7 y 8, lo que haces es sumar 7 + 8 y divides entre 2 y Md= 7.5. Eso es todo.
Existen dos métodos para el cálculo de la mediana:
- Considerando los datos en forma individual, sin agruparlos.
- Utilizando los datos agrupados en intervalos de clase.
A continuación veamos cada una de ellas.
[editar] Datos sin agrupar
Sean

los datos de una muestra
ordenada en orden creciente y designando la mediana como
Me, distinguimos dos casos:
a) Si
n es impar, la mediana es el valor que ocupa la posición
(n + 1) / 2 una vez que los datos han sido ordenados (en orden creciente o decreciente), porque éste es el valor central. Es decir:
Me = x(n + 1) / 2.
Por ejemplo, si tenemos 5 datos, que ordenados son:
x1 = 3,
x2 = 6,
x3 = 7,
x4 = 8,
x5 = 9 => El valor central es el tercero:
x(5 + 1) / 2 = x3 = 7. Este valor, que es la mediana de ese conjunto de datos, deja dos datos por debajo (
x1,
x2) y otros dos por encima de él (
x4,
x5).
b) Si
n es par, la mediana es la media aritmética de las dos observaciones centrales. Cuando
n es par, los dos datos que están en el centro de la muestra ocupan las posiciones
n / 2 y
n / 2 + 1. Es decir:
Me = (xn / 2 + (xn / 2 + 1)) / 2.
Por ejemplo, si tenemos 6 datos, que ordenados son:
x1 = 3,
x2 = 6,
x3 = 7,
x4 = 8,
x5 = 9,
x6 = 10 => Hay dos valores que están por debajo del
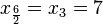
y otros dos que quedan por encima del siguiente dato

. Por tanto, la mediana de este grupo de datos es la media aritmética de estos dos datos:
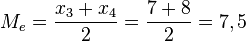
.
[editar] Datos agrupados
Al ratar con datos agrupados, si

coincide con el valor de una frecuencia acumulada, el valor de la mediana coincidirá con la
abscisa correspondiente. Si no coincide con el valor de ninguna abcisa, se calcula a través de semejanza de triángulos en el
histograma o polígono de frecuencias acumuladas, utilizando la siguiente equivalencia:

Dónde
Ni y
Ni − 1 son las frecuencias absolutas acumuladas tales que

,
ai − 1 y
ai son los extemos, interior y exterior, del intervalo donde se alcanza la mediana y
Me = ai − 1 es la abscisa a calcular, la moda. Se observa que
ai − ai − 1 es la amplitud de los intervalos seleccionados para el diagrama.
[editar] Ejemplos para datos sin agrupar
[editar] Ejemplo 1: Cantidad (N) impar de datos
| xi | fi | Ni |
|---|
| 1 | 2 | 2 |
|---|
| 2 | 2 | 4 |
|---|
| 3 | 4 | 8 |
|---|
| 4 | 5 | 13 |
|---|
| 5 | 8 | 21 > 19.5 |
|---|
| 6 | 9 | 30 |
|---|
| 7 | 3 | 33 |
|---|
| 8 | 4 | 37 |
|---|
| 9 | 2 | 39 |
|---|
Las calificaciones en la asignatura de Matemáticas de 39 alumnos de una clase viene dada por la siguiente tabla:
| Calificaciones | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|
| Número de alumnos | 2 | 2 | 4 | 5 | 8 | 9 | 3 | 4 | 2 |
|---|
Primero se hallan las frecuencias absolutas acumuladas
Ni. Así, aplicando la formula asociada a la mediana para n impar, se obtiene
X(39 + 1) / 2 = X20.
- Ni-1< n/2 < Ni = N19 < 19.5 < N20
Por tanto la mediana será el valor de la variable que ocupe el vigésimo lugar.En este ejemplo, 21 (frecuencia absoluta acumulada para Xi = 5) > 19.5 con lo que Me = 5 puntos, la mitad de la clase ha obtenido un 5 o menos, y la otra mitad un 5 o más.
[editar] Ejemplo 2 : Cantidad (N) par de datos
Las calificaciones en la asignatura de Matemáticas de 38 alumnos de una clase viene dada por la siguiente tabla (debajo):
| Calificaciones | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|
| Número de alumnos | 2 | 2 | 4 | 5 | 6 | 9 | 4 | 4 | 2 |
|---|
| xi | fi | Ni+w |
|---|
| 1 | 2 | 2 |
|---|
| 2 | 2 | 4 |
|---|
| 3 | 4 | 8 |
|---|
| 4 | 5 | 13 |
|---|
| 5 | 6 | 19 = 19 |
|---|
| 6 | 9 | 28 |
|---|
| 7 | 4 | 32 |
|---|
| 8 | 4 | 36 |
|---|
| 9 | 2 | 38 |
|---|
Primero se hallan las frecuencias absolutas acumuladas
Ni.
Ni. Así, aplicando la fórmula asociada a la mediana para n par, se obtiene Formula:
X = n / 2 = = > X = (38 / 2) = > X = 19 (Donde n= 38 alumnos divididos entre dos).
- Ni-1< n/2 < Ni = N18 < 19 < N19
Con lo cual la mediana será la media aritmética de los valores de la variable que ocupen el decimonoveno y el vigésimo lugar. En el ejemplo el lugar decimonoveno lo ocupa el 5 y el vigésimo el 6 con lo que Me = (5+6)/2 = 5,5 puntos, la mitad de la clase ha obtenido un 5,5 o menos y la otra mitad un 5,5 o más.
[editar] Ejemplo para datos agrupados
Entre 1.70 y 1.80 hay 3 estudiantes.
Entre 1.60 y 1.70 hay 5 estudiantes.
Entre 1.50 y 1.60 hay 2 estudiantes.

[editar] Método de cálculo general










 los datos de una muestra ordenada en orden creciente y designando la mediana como
los datos de una muestra ordenada en orden creciente y designando la mediana como 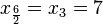 y otros dos que quedan por encima del siguiente dato
y otros dos que quedan por encima del siguiente dato  . Por tanto, la mediana de este grupo de datos es la media aritmética de estos dos datos:
. Por tanto, la mediana de este grupo de datos es la media aritmética de estos dos datos: 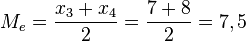 .
. coincide con el valor de una frecuencia acumulada, el valor de la mediana coincidirá con la
coincide con el valor de una frecuencia acumulada, el valor de la mediana coincidirá con la 
 ,
, 
